


Authors:
Angelika Strohmayer, Michael Muller

Below is the outcome of a meandering conversation we had over a video call. We covered many different topics from a variety of perspectives and disciplines. After recording our chat, we tried to edit it into a more structured conversation for this piece, but we also wanted to keep some of the meandering.
Michael Muller: Hi, Angelika! Would you be interested in talking a bit about "data-ing" and "un-data-ing" in HCI? In our CHI 2022 paper, we called into question the "objectivity" of data in machine learning. Along with Naja Holten Møller and Melanie Feinberg, we showed that humans shape the data in many ways. What are the implications for the "grand narratives" of data science, if the data are chosen, transformed, and even created by humans, and if the data are correspondingly dynamic and changeable?
Insights
→ Data become "data" when a human says they are data, and that happens only after humans transform the data.
→ Data as a material of analysis reflect both who says they are data, and what they and others want to do with the data.
→ What were to happen with our data practices if we moved beyond positivism and constructivism and instead allowed wonder, glow, and glitter into the process?
Angelika Strohmayer: Hi, Michael! Following on from that work, I'd like to think with you about what were to happen if we looked at data, in the data work and data science sense, differently?
MM: What if we start with the paper we wrote last year. In "Forgetting Practices in Data Sciences" [1], we talked about a lot of things related to Mimi Onuoha's [2] concept of data silences—systematic gaps in an otherwise rich dataset. In our analysis, datasets can be seen as dangerous or beneficial, but seldom neutral. We talked about selective legibility, or how data are ignored or suppressed; we picked up Joni Seager's idea that "what gets counted counts," and we built on that by talking about data genocide, where people say, "Oh well, there's not enough of those people to include in the dataset, or we certainly wouldn't separate them out and look at the differences in their circumstances." While all of this is happening, in an attempt to remain "objective" in data science work, we simultaneously want to assert that almost everything in our world is now data—data that is monetized—and that monetization and objectivity are often in service of different or even opposed priorities.
There are a lot of data practices, which, if unrecognized and unexamined, then allow data to be "the new oil," a seemingly homogeneous and interchangeable resource to be exploited, bought, sold, and, as Sandy Gould [3] showed, consumed as a commodity. After people have finished what the data scientists would call wrangling, what you and I might call data work, then the data just becomes a "resource"—almost an infrastructural resource, very much in the sense of Leigh Star and Geoffrey Bowker in Boundary Objects and Beyond, a thing that we don't really look at anymore. It's there, so we use it. It fades from consciousness. And then we tend to assume it's perfect and systematically forget all that's wrong with it, or we never find out because we bought it from someone. We need to ask questions like, What would data science look like if the data, where it came from and what it includes, were foregrounded?
What would data science look like if the data, where it came from and what it includes, were foregrounded?
AS: And I would add: What if we changed our frame of reference for defining and analyzing data? What would a data science be if we not only moved away from positivism but also talked about it entirely outside of positivism even as a frame of reference? When we're not just talking about qualitative analysis but also about a world that is post-qualitative and post-coding? What would a data science look like if rather than having a systematic reason to look into finding "a truth" or having a fully structured response or analysis, we started looking at the data from knowing our own positionality in relation to it, or if we framed it as meaningful exploration that is materially rather than academically useful for affected communities?
MM: This makes me think of epistemologies and standpoints. Sandra Harding developed a scientific community around the concept of standpoint epistemologies—in essence, as Donna Haraway said in "Situated Knowledges," there is no "view from nowhere." Data are always seen from somewhere, by someone, and during sometime. Context always matters, and context includes the human context of how data are declared to be data; how, as Melanie Feinberg says, data are designed; and how, as Helena Mentis says, data are crafted into useful representations. Those are academic ways of describing data. But what did you mean by "materially useful"?
AS: I think "materially useful" can mean lots of things, but ultimately for me it refers to usefulness that can make a difference or have a consequence. So, while that can refer to, for example, producing reports, tools, guidance, or other kinds of "things" that are useful for the people we work with or that relate to our research, the "material" can also be less tangible. For example, how can the research, and research process, be used to build shared understanding or experience? How can we use it to build more confidence, power, or knowledge for specific people or communities, or to ask ourselves what role our research can play beyond the outcomes? This is where the process can be really useful or important! I wonder if, or rather how, that also resonates in research that is much more focused on big datasets, or datasets that have been purchased?
MM: Well, eventually we have to accept our dataset and work with it. The kind of work that you do and the kind of work that I prefer to do with a dataset is to go incident by incident, interview by interview, observation by observation. We look at them and we say, "Well, this one is different from that one; and I know that for you that often relates to many contextual factors outside the 'dataset' as well. And oh, there's a bunch of records or observations that are different from another bunch." But a whole lot of HCI work with datasets doesn't work like that. We often want to "do things with datasets," losing detailed insights that we could find if we focused our attention inside the dataset. By which I mean focusing our attention on the data. At the level of the dataset, "the data"—usually perceived as a whole dataset—become infrastructural after a while, and that's not a healthy data practice.
AS: I recently came across Maggie MacLure's work related to post-qualitative analysis [4], which might be helpful in coming back to the detailed insights, and the ability to focus our attention back on those. She talks about our productive capacity of wonder in relation to our data, and in another article she talks about how in our data "some detail—a fieldnote fragment or video image—starts to glimmer, gathering our attention. Things both slow down and speed up at this point." Taking this affective approach into this conversation, I wonder what were to happen if we asked what a computing dataset would look like if we analyzed it for what glowed, in MacLure's sense, rather than for what was systematically included. Or if we acknowledged that the connections we make in the analytic processes continue to "smolder," as they do "not stop at the point of writing"? When we're talking about data genocide (as you did earlier), we're minimizing certain things because they're exclusions or data points that are far off and just "mess up" the data or stop it from being "significant." Or there are social pressures to ignore certain data because the data are socially or politically inconvenient, or because the people described by those data are socially or politically inconvenient. And as you said earlier, we often assume that when we're done, the data is done and becomes an infrastructure.
MM: Yes, I love your point about finding MacLure's wonder and glow, and being open to what those unusual or nonconformant data can tell us, or what worlds they might open for us. Shaowen Bardzell and Sandra Harding talk about the margins, and that that's where the information is. In her landmark 2010 paper, Bardzell wrote,
Feminist standpoint theory thus attempts to reconfigure the epistemic terrain and valorize the marginal perspectives of knowledge, so as to expose the unexamined assumptions of dominant epistemological paradigms, avoid distorted or one-sided accounts of social life, and generate new and critical questions [5].
I mean, the difference between "margin" and "outlier" versus "the core data" is just a question of numbers, an undersampling, which comes down to lack of access, lack of opportunity, lack of imagination, laziness, or exclusion: Data scientists haven't gone far enough down a certain direction or didn't go at all. This could be an example of a glowing that was not found: not acting on a discovery that there was something different in an "outlier" and noticing it as unusual and then marking it for exclusion rather than for further inquiry.
AS: So, what would a dataset look like, how would it be "wrangled" and "cleaned" if we created it for exploration, allowing us to follow it based on wonder or glow rather than attempting to seek a "truth"?
MM: And what if rather than trying to corral the dataset into being "well behaved" in the conventional way, we instead allowed it to make good trouble (borrowing a concept from John Lewis), to disrupt, to be unruly in the liberatory sense? What if we were looking for trouble, staying (as Donna Haraway says) with the trouble, rather than "good data behavior?"
AS: There's this really wonderful paper called "Glitter: A Methodology of Following the Material" by Rebecca Coleman [6]. She talks about following glitter in a workshop setting and how it goes into all the nooks and crannies, how it lingers and can never fully be gotten rid of. It can take different routes, routes that are material rather than simply based on "data."
MM: That resonates strongly for me. I've been rereading Donald Schön's [7] paper "Designing as Reflective Conversation with the Materials of a Design Situation." The paper is such a deep look at the experience of designing and the experience of having the design materials talk back at you. Schön points out that design materials may be literal—like a visit to a design site—or representational (like a sketch or a display on a screen). I think the important aspect may be that we think while we design, and that what we design—the materials in our design—inform our thinking. Or we think and we design, and it's all one activity. When we work with the data in a dataset, do the data also talk back to us? I think they do. And I think we do better analyses when we open ourselves to what the data have to tell us. Similarly, in our 2019 and 2021 CHI papers, we talked about data scientists often having a "feel for the data" as well—like a feel for the clay if you're doing ceramics, or for the wool if you're weaving. Or how in your embroidery, the materials talk back to you all the time too.
AS: This reminds me of an embroidery piece I made and how I worked with the materials, giving space for them to respond to my actions and then trying to hold steady the movements that were made by the threads and yarn—and how that made me think of research (Figure 1).
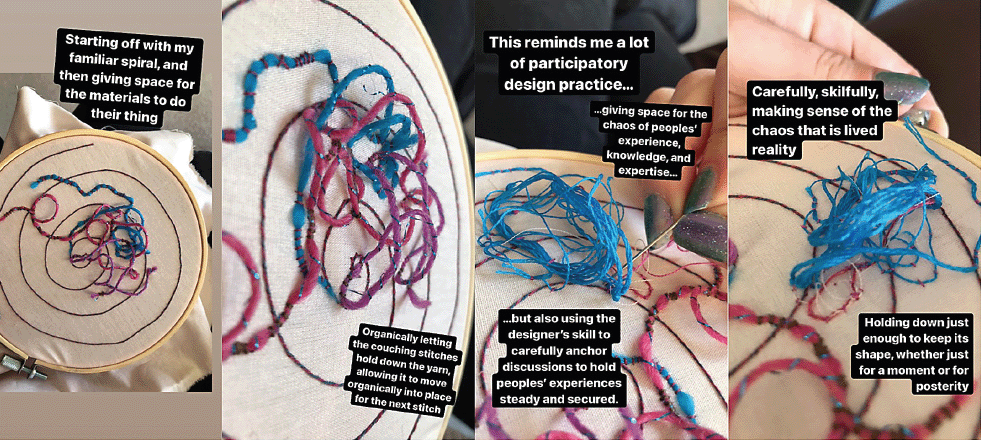 | Figure 1. Annotated photos of an embroidery process and reflection carried out by Angelika. |
But I guess the difference is that in the craft settings you talk about, that material being part of the process is acknowledged and appreciated, and often wanted; whereas in the data science settings it's trying to be objective.
MM: Yes, or it's actually considered a source of problems and so then you try to beat them out of the data. Do you know the ancient Greek tradition of Procrustes?
AS: No.
MM: It's a horror story in Greek mythology because it shows a violation of the cultural importance of hospitality. Procrustes would invite people to his house. He would feed them a nice dinner. Then he would say, "Here's the bed you can sleep in," and if they were tall he would lop off the parts that were longer than the bed. If they were short he would beat them until they spread out to cover the full base of the bed. People have actually talked about "Procrustean analysis," although not for several decades—sometimes I think that's what we do with our data. We lop off the parts we don't like. We beat the parts that are otherwise nonconformant.
AS: What if instead of doing that—which sounds quite dangerous and very far from what we would call a truth to me—we stuck with the data, followed it in Coleman's glitter sense? She writes, "I understand following glitter both in terms of a methodology that is responsive to the liveliness of objects and materials, and also as particularly appropriate to glitter as a material; a collection of tiny reflective or shiny pieces of plastic, or more recently biodegradable materials, one of its properties is its tendency to disperse, spread and scatter." What if we let the material of the data use its reflective pieces to shine, disperse, scatter, or, in the craft sense we talked about before, become a part of the meaning-making process?
MM: In Theoretical Sensitivity, Barney Glaser asked, "What is this data a study of?" I think he was saying that "the story in the data" has to be discovered incrementally, through immersion in the data. In Constructing Grounded Theory, Kathy Charmaz would say that the story has to be constructed. In the scenario that we're discussing, we've not yet decided what the story is. I think some practitioners of grounded theory might resonate very much with what you've described from the glitter paper—which is exciting to me because I think that's where we're going to find the new stuff, rather than in the hypotheses that we already know to test. And Schön might have agreed, too, that discovery can happen when the data (in his case, the design materials) speak back to us.
AS: Interestingly, more and more I don't always want to call things data because it can dehumanize everything it asks for. To me, the word data asks for positivism, and asks for truth and evidence and all of these things that I'm not necessarily looking for in my research. Similarly with the words data analysis or just analysis you present a certain epistemology and ontology: A colleague reminded me recently that you can also explore, you can refine. In response to this, I initially countered that all those words were a form of analysis, but she continued saying something along the lines of "but they don't have to be." They can just be explorations. Data can just be. And our work can relate to exploring and reshaping, reconstructing, following, noticing. Looking back at the conversation now, I think I understand more of what she meant.
MM: Analysis, as conceived in data science, can often be constructed very narrowly as hypothesis testing, or beyond data science very broadly as an organized description or series of inferences. In other (sub)disciplines, the concept of analysis can be much broader. It can describe how we think when we approach something that puzzles us or something that we want to work with. For some researchers, sensemaking (formal or informal) is a kind of tacit analysis that all of us humans do, all the time. In a different paper, Schön claimed that most or all professional practice is like design—a search for patterns, with an emphasis on patterns that can be of use.
AS: So I come back to the question: What would a data science look like if it sat outside the positivist frame it's currently in? Going further than Catherine D'Ignazio and Lauren Klein's Data Feminism [8], I wonder what a data science would look like if we gave space for the material to speak and if we acknowledged and responded to this? What would a data science look like if we were to define what its glitter might be and if we were then to follow it? What would the glitter of data science be and what might happen if we followed its materiality effectively? With traction, with friction, looking at what it is and what it does rather than just trying to define it? What would a data science look like if we let our positionality into the data and if we allowed the glitter to shine, if we followed its glow? Would such a data science even be possible? Or would data science co-opt this language, turning it into positivist goop?
MM: In some ways, I think you are advocating that data science should be conducted in-the-large and also in-the-small. I think you've been saying that it's in-the-small where glow and glitter are more likely to become visible—perhaps exactly because these pathways into new insights often occur at the margins, or where we don't think we need to be looking, like a firefly at the edge of our vision? Or even if we are paying attention, it's like Maya C. Popa's poem "All That Is Made" [9]:
that every bright thing has at its heart a hiddenness it offers when you've just about stopped looking
We've seen recent work to (re)introduce qualitative analysis to large-scale quantitative data science work, from the HCI, NeurIPS, and feminisms discourses. I feel like we're still figuring out how to do this. Maybe adding ideas of wonder, glow, and glitter might be in this setting, and might help?
AS: I do wonder what were to happen to data science work if researchers went beyond the idea of qualitative analysis and looked beyond positivism. But I am almost even more curious about how far we can push that—what might happen if we moved beyond a post-constructivist frame and meaningfully incorporated materiality and onto-epistemologies of new materialism into the mix? What would glitter look like in a dataset? How would we be able to follow it? And coming back to our thinking from the paper with which we started this conversation: How would we document and discuss this process to avoid creating further silences in data work? I like to think that the world of AI and NLP would, and could, look very different if we started to think and do differently.
References
1. Muller, M. and Strohmayer, A. Forgetting practices in the data sciences. Proc. of CHI Conference on Human Factors in Computing Systems. ACM, New York, 2022, 1–19.
2. Onuoha, M. The library of missing datasets. 2016; https://mimionuoha.com/the-library-of-missing-datasets.
3. Gould, S.J.J. Consumption experiences in the research process. Proc. of the CHI Conference on Human Factors in Computing Systems. ACM, New York, 2022, 1–17.
4. MacLure, M. Researching without representation? Language and materiality in post-qualitative methodology. International Journal of Qualitative Studies in Education 26, 6 (2013), 658–667.
5. Bardzell, S. Feminist HCI: Taking stock and outlining an agenda for design. Proc. of the SIGCHI Conference on Human Factors in Computing Systems. ACM, New York, 2010, 1301–1310.
6. Coleman, R. Glitter: A methodology of following the material. MAI: Feminism and Visual Culture 4 (2019).
7. Schön, D.A. Designing as reflective conversation with the materials of a design situation. Knowledge-based Systems 5, 1 (1992), 3–14
8. D'Ignazio, C. and Klein, L.F. Data Feminism. MIT Press, 2020.
9. Popa, M.C. Wound Is the Origin of Wonder: Poems. W.W. Norton, 2022.
Authors
Angelika Strohmayer is an assistant professor in the Northumbria University School of Design. She works closely with third-sector organizations, activists, and other stakeholders to creatively integrate digital technologies in service delivery and advocacy work, using feminist participatory action research, research through design, creative practice, and social justice. [email protected]
Michael Muller is a senior research scientist at IBM Research. His research occurs in the hybrid intersection of critical computing, HCI, AI, and social justice, using participatory and values-based methods. [email protected]
Copyright held by authors
The Digital Library is published by the Association for Computing Machinery. Copyright © 2023 ACM, Inc.




Post Comment
No Comments Found