


Authors: Caroline Sinders
Posted: Mon, June 01, 2020 - 10:16:42
The city of Amsterdam is using artificial intelligence (AI) to help sort through and triage their version of 311 calls. Chicago is using AI to help analyze and decrease rat infestations and to prevent them in the future. There is value in applying AI to urban challenges, but that value must come with explicit protections to privacy and citizen safety. AI has known issues with bias, from a widely documented inability to recognize different genders and races to its use in predictive policing. Thus, when using AI as infrastructure or in technology that interacts with society, safeguards must be put into place to mitigate harm. When, how, and why we use AI must be analyzed and unpacked. This article will examine a potential use case for using AI in understanding city and civic data, and the potential benefits as well as harms that could arise.
What data is right for civic challenges?
The power of AI is that it can recognize patterns at scale and offer insights and predictions. For civic technology, this may be a great way to see patterns across a city to potentially prompt deep investigations into recurring mold, faulty pipes, and potholes across neighborhoods and larger districts. These problems should be viewed as data; for example, the reports that citizens make are data. Data is important—it's the backbone of artificial intelligence. Smart cities, IoT devices, and open government initiatives are all creating astounding amounts of data. Data presents stories about the people who live in the communities and cities where the data was gathered, and this data must be safeguarded against all different kinds of bad actors. Every data point from a software application, from the amount of usage to data from a social network, is made by humans. Meaning, data isn’t just something cold or quantitative; it’s inherently human. Thus, the privacy and transparency of datasets—who collects it and how it’s stored—is incredibly important.
The problem, and the lynchpin, with using AI will always be data. Data can be messy and unstructured, so even before thinking about using AI, one has to ask: Does the data we need even exist? If so, is our dataset big enough? Is it structured? And there is always the moral quandary: Do we really need AI here or does a city or community just need more human power behind this problem?
AI in cities...right now
The city of Amsterdam is using AI to help sort through their version of 311 calls (free service-request calls in cities ) in a product called Signal (Figure 1). Residents can file requests about issues in public spaces through calls, social media, or a Web forum. Tamas Erkelens, program manager of the Chief Technology Office innovation team that built Signal, told me in an interview about the process that routs service requests, saying that users had to pick their own categories. But, as he said, “Users think in problems and not in governmental categories. Instead, we started asking users to describe the problem or take a photo, and we use machine learning or computer vision to [help sort the problems].” Signal uses AI to help sort residents’ requests into different categories, following the logic of the user to put residents—and residents’ frustrations—first as a priority for complaint triage. Erkelens also told me that his team has successfully created a model capable of detecting more than 60 categories in the Dutch language but that the system is also audited by a person. This human auditing is important to ensure safety and understanding. Even when we leverage AI to handle an influx of complaints, humans are still needed to assure quality.
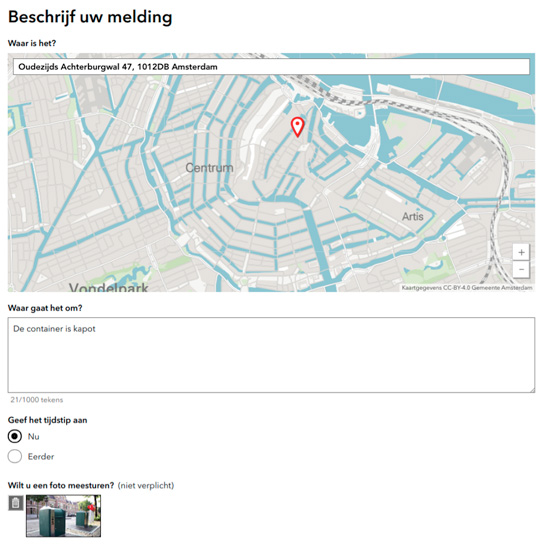
Figure 1. Screenshot from Amsterdam’s Signal app.
Data: It’s more than just numbers
When working with civic technology and data initiatives from local, state, and federal governments, a variety of problems can pop up. Generally, there may not be similar data standards across cities, or even across the same city’s various departments, and datasets can be of differing sizes and structures. Comparing or combining data from different municipalities can be difficult. As Georgia Bullen, executive director of Simply Secure, a nonprofit focusing on privacy and design, explained, "A lot of the big problems internally for cities are actually that different departments have different datasets, and it’s really hard to combine them...Cities are storing data in different ways, and they have different policies in place that affect what those values even mean.”
When integrating any form of technology into civic and civil services, the technology itself coupled with the service it’s intended to augment must be viewed holistically within the context of a service design problem. That is, if an app is trying to help solve the problem of how to reduce the number of residents contacting the city over potholes, the app combined with the city service must be viewed as an integrated and holistic problem under the service design for the user experience of contacting the city. What kind of biases or issues can the app add? What kind of unintentional hierarchies can it create? How much data is it creating, and how is that data stored? These are some questions that designers and engineers can ask in this situation.
We can look at the New York City’s 311 as an example of unintended design consequences. A 311-type of system can lead to the police being called, even unnecessarily, when the system is very easy to use, or because of patterns learned by machine learning. As Noel Hidalgo of Beta NYC, a civic technology organization, says, “It’s really easy to file a noise complaint on the 311 app.” The 311 app promotes noise complaints as something you can report using the service. In the app, when a user selects “apartment” to denote more information about the noise complaint, the police immediately become notified. So even if a user is just trying to report a noise complaint without contacting the police, they actually can’t do that because of how the app is designed.
The problem with this design for 311 is that it relies on a belief in government to respond to your needs. For a lot of citizens, government can be a thing to fear, such as neighborhoods of color who face over-policing or gentrification, which can lead to clashes among new and old residents. For some citizens, their local and federal governments, including 311, are not systems that they can necessarily trust. There are so many facets to the way in which a governmental system can be used, but do citizens understand that, and does the AI model reflect all of these facets? The model and AI system must be designed for how citizens actually interact with governmental systems, meaning that they may not completely understand or fully use 311 (e.g., calling reactively instead of preemptively). Yet the system must also be designed for how the city or government needs it to be used. This means 311 should be designed for both reactive and preemptive reports.
A real-world example
As an example, let’s unpack Million Trees NYC, a citywide, publicly and privately funded program to plant one million trees in New York City from 2007 to 2015. If a researcher wanted to use machine learning to understand why certain trees are planted in certain parts of New York City, that researcher would need to consider a number of factors, from different boroughs’ tree-planting budgets, to soil conditions, to tree prices and availability, to the resources available in different neighborhoods to water and care for the trees, to the specific cost-benefit analyses of planting in certain postal codes. And then other questions come up: How many trees existed before?
Million Trees NYC could hypothetically use AI to discover which tree types were successful, meaning which trees grew and flourished, and where they grew and flourished, to help determine optimal conditions for tree planting. Even posing this question raises more questions. Can we assume that wealthier neighborhoods get more trees? If not, do trees survive at the same rate across New York City? Across New York State? Exploring this data just to find a problem to solve requires asking many initial questions. A researcher would need the additional expertise of understanding all of the factors listed above and more to find the right dataset and build the right model. The deeper data story isn’t just that rent is high in the New York City borough of Manhattan versus Queens. It’s that even planting trees is complicated by policy, history, and other systems. Using any robust system like AI to unpack large datasets can help call out systemic inequity in cities, but the datasets themselves must also be analyzed. Intention is important.
Data is complex. What is needed to make the data more whole?
A dataset is so much more than the initial spreadsheet you have. What are the factors that contributed to that dataset? Those factors not captured in your initial dataset are the factors that make it more whole. A first step when working with data is to outline all of the related data pieces, similar to a recipe. Bread isn’t just flour and water; it’s flour that is sifted, to which a certain amount of water is then added. With my trees example, I picked the data apart: Where are trees in New York City currently? Historically? What kinds? More important, how do we know what makes a tree healthy?
Bullen stresses that we ask specific questions, such as what makes a tree survive? Can we extrapolate that from data? And what makes the money spent on that tree useful? That is, if planting a tree costs X amount of money, what about really growing and caring for that tree? Were the tree box filters big enough for the root systems? What were the weather conditions, and who is responsible for caring for the tree?
All of those factors—weather, tree box filter size, kind of tree, history of the neighborhood, environmental history—are related to the Million Trees dataset, even if those data points aren’t captured in that one dataset. All of these types of factors are not just questions, but also data points that need to be interrogated while collecting and analyzing data.
Don’t just identify, but question and audit patterns in the data
When a pattern emerges from a dataset, don’t take it at face value. Ask: Why is this occurring? Is it correct? Does it feel right? What would happen if this was wrong? What would the real-world outcomes be? Would it cause any person real-world harm? Whatever question you’re analyzing, try asking it from the opposite point of view. For example, when analyzing what makes a tree healthy and looking at neighborhoods that have healthy trees, look into what kinds of trees you’re looking at, and ask: What is the history of those neighborhoods? Now try analyzing unhealthy trees and look for whether this refers to the same tree types. What season were they planted in? Historically, what trees were in that neighborhood? You might find how a city has changed over many decades. For example, a highway that cuts across a neighborhood or borough can have downstream affects of radically changing that neighborhood. A highway adds noise and air pollution, which in turn can cause lower property values. This kind of historical analysis needs to be taken into account with city data, and in this case, tree data. Data has so many other kinds of factors that can affect outcomes.
What are the parallel and contextual data related to this dataset?
From the dataset, can you tell if trees that are dying are dying in neighborhoods that have been systematically underserved? And how do you put that into context? Think about parallel context data: What else has happened in these spaces in the past 20 years? 30 years? Bullen points out that a lot of the datasets for civic technology may be only 10 years old, and that there may not be a lot of available historical data. The patterns coming out of your dataset are made up of so many nuances, with historical roots in policies such as gentrification, segregation, and redlining, which may be reflected in technology. A city is complex, so a dataset, even about trees, will have all of the complexities and biases of a city (such as redlining or segregation) built into it.
Expanding the idea of bad data
Bad data isn’t necessarily harmful data, or data that seems adversarial at first glance. It’s data that is incomplete. Examples of this can appear when analyzing the dataset about trees and how well trees grew in different parts of New York. There are a lot of factors that affect tree growth that aren’t in that dataset. This kind of fuller reasoning makes the Million Trees dataset incomplete and it needs to be viewed as such.
Bringing intersectionality to data
Designing for cities, without AI, is already a nuanced, thorny, large, and, at times, difficult problem. It is a wicked design problem, bound by legislation, bureaucracy, architecture, and then technology, as cities themselves and those who work in civic technology update to keep up with changing technology. Technology affects cities across the board, from the architecture, hardware, and design of cities that are becoming “smarter” cities, to the software and processes of civil servants updating cities with new kinds of technology. Adding AI into the mix is not easy and shouldn’t be engaged with as a kind of pan-techno-solutionism, even when looking at something as seemingly benign as tree-planting data. As it’s been outlined in this article and in other published examples, AI and technology writ large amplifies bias and injustice, regardless of how complete or incomplete a dataset is. But AI could be used effectively if we unpack how deep technology solutions inside of cities work, and where AI would fit into the mix on top of preexisting technology. Technology alone doesn’t solve problems and can create unforeseen problems, as we see specifically with 311; those issues must also be scrutinized. What is the line between calling 311 to fix a problem and the solution to that problem being to deploy a police car? Are users aware of what the response will be when placing a 311 call? This kind of response needs to be unpacked, examined, and then fixed. This similar kind of interrogation must be applied to AI as well. Cities have a diversity of inhabitants, and that means a diversity of responses to problems. So how technology responds to, sorts, and understands those issues and then provides solutions must always be analyzed as potential design flaws, as well as policy flaws when the solutions result in unintended harm. Moving forward, all technology, including AI, must take an intersectional perspective, especially in cities, where historical racism and injustice were a part of the status quo, and the legacy of that injustice is still affecting data and design in cities around us today.
Posted in: on Mon, June 01, 2020 - 10:16:42
Caroline Sinders

View All Caroline Sinders's Posts


Post Comment
No Comments Found