


Authors:
Armağan Karahanoğlu, Aykut Coşkun

We have a plethora of digital tools at our fingertips for understanding our bodies, from activity trackers to smartwatches. Through these tools, we are not just recording our lives; we are quantifying them, owing to the affordability and accessibility of sensing and networking technologies, which empower us to track various health indicators such as heart rate variability (HRV) and stress scores.
Insights
→ We propose four modes of data sensemaking, which are about turning numbers and data into a story that self-trackers can relate to, understand, and use, taking a big step toward helping people make healthier choices.
→ We emphasize the importance of research and guidance for designers to empower individuals to gain meaningful insights from their health data.
While the initial wave of health trackers focused on quantifying bodily metrics, the tide is turning toward more qualitative, subjective, and social-oriented tracking practices that capture lived experiences [1]. Digital data has turned the process of reflection into a sensory experience, fundamentally altering how individuals perceive and interact with their data. Self-tracking is no longer about sterile numbers and graphs, but rather about creating a personalized narrative that resonates with an individual's goals, desires, dreams, and feelings. It is not only about how many steps you take but also what those steps mean for your daily life, how they make you feel, the social interactions they lead to, and the broader context in which they occur.
But are we truly harnessing the power of this data or merely drowning in an ocean of numbers? This article explores this question from the data sensemaking perspective.
Four Modes of Data Sensemaking in Self-Tracking
Extracting meaningful insights from personal health data is challenging given the complex and multifaceted nature of self-tracking through technology. It is not uncommon to see an influx of individuals tracking their health who get confused about what specific values indicate, especially when the values are not easy to understand, as was previously reported in several HCI studies [2,3,4]. Consequently, merely collecting data is not enough anymore: The actual value lies in making sense of data, transforming it from abstract numbers into actionable insights. This process demands cognitive engagement and deeper interaction with data. In parallel with this challenge, there is a growing fascination in HCI with the intricate data sensemaking processes that individuals undertake when they collect, analyze, and reflect on their health data. How people make sense of their data and how tracking technology could support their sensemaking practices, however, remain underex-plored questions in the field.

In our work, we addressed this gap and examined sensemaking practices in self-tracking by conducting a systematic review. Ultimately, we identified four modes of data sensemaking [5]: self-calibration, data augmentation, data handling, and realization (Figure 1). Although we present the modes in a particular order here, our framework does not suggest that a self-tracker follows a linear path toward data sensemaking. Every self-tracker has a unique sensemaking journey: Some may start with data handling, others begin with self-calibration, and others may not engage in data augmentation.
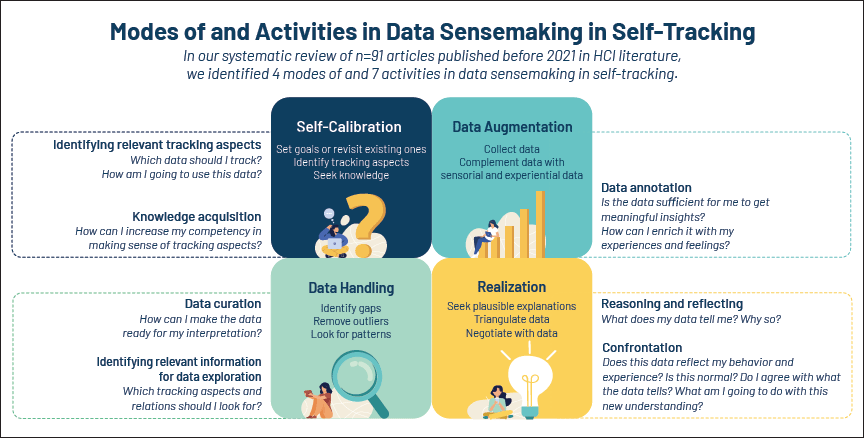 | Figure 1. Four modes of data sensemaking. |
Here, we present these modes as a framework to better inform the design of human-technology interactions that support self-trackers' data sensemaking process, providing designers with actionable starting points for designing such interactions. We explain these modes and use "stress data sensemaking" as exemplars to better contextualize our framework.
Self-calibration: Setting the tone and personalizing the journey. In the self-calibration mode, individuals embark on a dynamic journey of setting goals, selecting relevant tracking aspects, acquiring knowledge about their bodies and conditions, and continually fine-tuning their approach to self-tracking. This mode is characterized by a proactive approach, where self-trackers actively acquire knowledge about their bodies and health conditions, leveraging a variety of tools and resources to gain insights into their well-being. For instance, recent fitness trackers such as those made by Fitbit (https://www.fitbit.com/global/nl/technology/stress) and Garmin (https://bit.ly/4efafuQ), allow users to track their stress score, which is calculated based on the HRV over time. In self-calibration mode, some individuals may consult with online support groups and forums and discover the significance of tracking HRV as an indicator of stress.
Self-calibration involves a continuous loop of monitoring, learning, and adjusting. As self-trackers gather data, they become more attuned to the nuances of their health and are better equipped to interpret the signals their bodies send. This heightened awareness enables them to fine-tune their approach, customizing the parameters and metrics to better align with their health objectives and lifestyle choices.
Imagine you have had a particularly hectic week at work. Your tracker indicates elevated stress levels, and you want to take action. In the self-calibration mode, you start by defining what you want to achieve with stress tracking. For instance, your goal could be to reduce stress levels by 20 percent over the next three months or to identify the primary sources of stress in your life. You would decide what specific data points are essential to track to meet your goals. This identification could include monitoring physiological stress indicators, such as HRV or sleep patterns. You might also decide to log subjective measures of stress, like daily self-rated stress scores or mood. You would then learn more about stress and its effects on the body and mind. You might even research how different activities or habits, such as exercise, meditation, or time management techniques, can influence stress levels.
Data augmentation: Infusing data with subjectivity and felt experiences. As self-trackers become more proficient in understanding and utilizing the quantitative data generated, they often recognize the limitations of these metrics. While quantitative data is valuable for tracking progress, it may not capture the full spectrum of an individual's health experience. This is where the self-calibration mode naturally transitions to the data augmentation mode, in which individuals enhance digital data collected from self-tracking tools by infusing it with their subjective observations and perceptions, often through data-annotation activities.
Through data annotation, self-trackers contribute to data collection by editing and enriching automatically generated data with personal notes or visuals, expressing their feelings and experiences. Annotating data brings several benefits to sensemaking, including giving data a personal touch aligned with self-trackers' identities, fostering a sense of ownership and agency, allowing for alternative interpretations of data, and encouraging real-time reflections that can affect future activities.
Imagine that your tracker records a spike in stress every weekday at 2 p.m. On its own, this is just a recurring data point. You then take a moment to check your stress level and annotate what you are doing at that time, how you are feeling, and any external factors contributing to your stress. Then, your annotations reveal a pattern that your mid-afternoon stress often coincides with meetings, particularly in uncomfortable environments or when there are external distractions. Such personalized annotations allow you to make sense of your stress data beyond mere numbers. This augmentation would provide a fuller picture of your stress triggers.
Data handling: Preparing data for interpretation and insight. The data-handling mode is where individuals engage in various activities to prepare their collected data for analysis, categorizing and interpreting it in a user-friendly way to unearth meaningful insights. With the vast amount of data that health trackers can collect, self-trackers can get easily overwhelmed, which can be prevented by two data-handling activities: data curation and identifying relevant information for data exploration.
Data curation entails reviewing, selecting, and prioritizing different data types to align them with individuals' information needs. Identifying relevant information for data exploration is equally crucial as self-trackers search for variations and patterns in their data, uncovering valuable insights into their behaviors and conditions.
For stress tracking, handling data could mean reviewing the extensive data you have collected from your wearable tracker and your annotated notes. You have several months of data on your HRV, sleep quality, physical activity, subjective stress ratings, and personal annotations about your mood, environmental factors, and specific stress triggers. At this stage, you prioritize the data that aligns with your stress-management goals. You decide to focus on physiological stress indicators and your annotations that seem to have the most significant impact on your stress levels. This could help you observe that your heart rate tends to spike during mid-afternoon meetings and when you have had fewer than six hours of sleep, while focusing on the most relevant metrics for your life.
Realization mode: Unveiling insights. In the realization mode, individuals analyze data patterns, often with contextual information, to understand their progress toward goals. Realization goes beyond mere observation, involving deep cognitive engagement with the information at hand to derive meaning and insight. This mode encompasses reasoning, reflecting, and confronting information extracted from data. During the reasoning activity, individuals examine the data patterns in the context of their personal goals and experiences. This involves dissecting the data to understand the underlying causes and effects of their behaviors and states. They ask a series of why and how questions that probe into the nature of the data correlations and the potential reasons behind them.
Reflecting is a more introspective process during which individuals consider the implications of their data concerning their self-perception and life circumstances. It is a moment of self-assessment, where the data acts as a mirror reflecting on one's habits, choices, and the efficacy of past interventions. This stage often involves reevaluating personal goals and strategies in light of new information, leading to a deeper understanding of oneself.
Confrontation is perhaps the most challenging step within the realization mode. It is where individuals face the realities that their data presents, which may confirm or challenge their preconceptions and intentions. Confrontation can lead to cognitive dissonance, forcing individuals to reconcile their perceived self with the empirical evidence of their behaviors and stress patterns. This step is crucial for growth and change, as it prompts individuals to make decisions on how to respond to their data, potentially leading to adjustments in behavior, adopting new coping strategies, or even overhauling their goals.
In essence, the realization mode is about integrating data into one's narrative, allowing for informed decision making and self-improvement. It is the stage where data transitions from a mere collection of numbers and notes to a catalyst for personal development and behavioral decisions.
For example, when you realize that your stress levels increase when you are in mid-afternoon meetings and have had fewer than six hours of sleep, you might make some adjustments in your daily schedules. Alternatively, you can challenge this stress data and start searching for more information regarding how stress is triggered to make sound decisions about your life.
Conclusion: Can We Design for Data Sensemaking?
The framework we presented here is a way to explain how self-trackers make sense of their data, translating them from numbers into meaningful insights. Understanding the data sensemaking process, however, is only the first step in designing for data sensemaking. Developing a new generation of tools that support individuals' sensemaking practices is a significant challenge. We note, though, that the ability to empower individuals to gain meaningful insights from their health data is not only a technological endeavor but also a profound human experience that can lead to healthier, more informed, and more fulfilling lives. This is not just a step forward in technology—it is a leap toward assisting people to live healthier and more informed lives.
As we move forward, recognizing and embracing these personal differences in the design of self-tracking devices will be crucial to their success and will help users genuinely benefit from the insights their health data can provide. Yet the journey for data sensemaking is just at its beginning, and the possibilities are endless. In a world filled with data, it is not only about what we collect but also about how we make it meaningful and effective in our lives.
References
1. Rooksby, J., Rost, M., Morrison, A., and Chalmers, M. Personal tracking as lived informatics. Proc. of the SIGCHI Conference on Human Factors in Computing Systems. ACM, New York, 2014, 1163–1172.
2. Hollis, V., Pekurovsky, A., Wu, E., and Whittaker, S. On being told how we feel: How algorithmic sensor feedback influences emotion perception. Proc. of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies 2, 3 (2018), 1–31.
3. Koesten, L., Gregory, K., Groth, P., and Simperl, E. Talking datasets—Under-standing data sensemaking behaviours. Intl. Journal of Human-Computer Studies 146 (Feb. 2021), 102562. https://doi.org/10.1016/j.ijhcs.2020.102562
4. Victorelli, E.Z., Dos Reis, J.C., Hornung, H., and Prado, A.B. Understanding human-data interaction: Literature review and recommendations for design. Intl. Journal of Human-Computer Studies 134 (Feb. 2020), 13–32; https://doi.org/10.1016/j.ijhcs.2019.09.004
5. Coşkun, A. and Karahanoğlu, A. Data sensemaking in self-tracking: Towards a new generation of self-tracking tools. Intl. Journal of Human-Computer Interaction 39, 12 (2023), 2339–2360; https://doi.org/10.1080/10447318.2022.2075637
Authors
Armağan Karahanoğlu is an assistant professor in interaction design at the University of Twente. Her work combines physiology and psychology with interaction design in understanding and designing human-technology interactions. As a human-centered designer and design researcher, she studies the effects of lifestyle tracking on people's health and well-being. [email protected]
Aykut Coşkun is an associate professor of design in Koç University's media and visual arts department and associate director of Koç University Arcelik Research for Creative Industries (KUAR). He has a B.Sc., an M.Sc., and a Ph.D. in industrial design and attended Carnegie Mellon University's Human-Computer Interaction Institute as a Fulbright scholar. His research focuses on design for behavioral change, design for sustainability, and design for well-being. [email protected]
 Licensed under a Creative Commons Attribution-Noncommercial International 4.0 license.
Licensed under a Creative Commons Attribution-Noncommercial International 4.0 license.
The Digital Library is published by the Association for Computing Machinery. Copyright © 2024 ACM, Inc.




Post Comment
No Comments Found