


Authors:
Tanya Kraljic, Michal Lahav

In late 2022, ChatGPT was launched and captured the public's imagination, as well as that of the tech industry. It was an AI with human-like language capabilities. For many users, it was a turning point, the first time they were consciously aware they were interacting with AI. For the design community, it brought an exciting opportunity to define the third human-computer interaction paradigm in computing history [1].

But just a few short months later, it feels like we're already becoming limited in our imaginations for what this new paradigm can be. "Prompt engineering" has emerged as the primary way forward to interact with generative AIs. Prompt engineering is the practice of designing and refining questions or instructions to elicit specific responses from AI models, and it squarely places the onus on the user to construct and adapt their query to maximize successful results from the system. Already an entire industry of books and courses (Figure 1) has sprung up to teach users how to control and direct the output of large language models (LLMs) by inputting the right kind of highly specific text strings. For a technology that aims to have humanlike capabilities, that doesn't sound like a very humanlike interaction paradigm. ChatGPT and others like it are already becoming tools for experts, rather than an HCI paradigm for the masses.
 | Figure 1. A bookcase in Japan dedicated to guides on how to use and master ChatGPT. |
Insights
→ Language is inherently collaborative, but AI interfaces don't yet leverage this power; they largely approach language as query-response.
→ Users need language-based AI to help them shape their intents and domain knowledge.
→ We can achieve this by investing in social and contextual reasoning capabilities, fostering interactions that build toward mutual understanding.
What does this look like in practice? Figure 2 shows one example of the kind of prompts people are teaching themselves—and one another—to write. This prompt appears in the training for Stable Diffusion, but you can find similar, self-generated examples on social media. There are even marketplaces where people can buy and sell prompts (e.g., PromptBase).
 | Figure 2. An example showing users of Stable Diffusion how they can phrase their prompts to get the system to produce the exact image they want. |
To make this technology more usable and accessible, designers and technologists working to improve the interface talk about integrating dashboards, sliders, and other visual elements as tools that help create the perfect prompt (Figure 3).
 | Figure 3. Visual sliders in Stable Diffusion. |
Of course, it makes sense to integrate visuals into any language-based interaction; communication is inherently multimodal, and when there are multiple modes available, we should leverage the strengths of each modality to contribute to the ease of the interaction (see [2] for a brief overview).
But how did we so quickly limit our imagination of what language interfaces can do for us, and with us? Why is there so much discussion of prompt engineering as the future paradigm describing language interactions with generative AI? It's one tool in our arsenal, one that's useful for experts and in those cases where someone knows, and can (with some effort) articulate, exactly what they want. But it certainly isn't natural language as people use it, and it doesn't leverage the strength of language as a tool for mutual understanding. If language interfaces themselves can't be usable by the masses and without manuals, that's a limitation of the current technology, not an inevitability.
The Old Metaphor: Language is for Encoding Meaning
It turns out current language technologies (and perhaps our imaginations for them) reflect an old but powerful theory of language as a symbolic system we use to transmit information to one another: A speaker encodes their thoughts and ideas into symbols (words), and a listener decodes those words back into meaning. This message-focused view is called the conduit metaphor [3] (Figure 4). In this view, meaning begins in one person's mind, and is packaged up in words and passed over to another person to unwrap and understand. The other person then packages up their response and hands it back over. Meaning exists "in" the words or sentences, and as long as two people or systems use the same encoding and decoding rules, communication should succeed. While such a model is intuitively appealing, we now know this isn't how language interactions work.
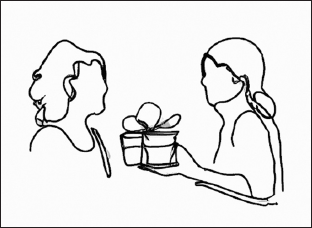 | Figure 4. Language-as-conduit metaphor: One person packages up their thoughts using words and hands that package over to the other person, who then decodes them in their own mind. In that way, information is "passed" back and forth. (Image created by the author using DALL-E.) |
Nevertheless, this conduit metaphor has been extremely influential in our technological approach to language from the very beginning of the field, and it's reflected in today's largely one-shot approaches to language interfaces. With these technologies, it's up to the user to figure out what they mean, and how to package that meaning into a specific ask the AI can decode. The more specific and clear a person can learn to be when translating their meaning into words, the more they enable the AI to get to an accurate understanding and provide a good response. This model explicitly or implicitly underlies every language technology, from command line interfaces to natural language systems to today's GenAI and prompt engineering.
And people have long sensed this locus of responsibility. "I guess I didn't say it right" or "I need to be clearer" are extremely common reactions to not being understood by a language technology, whether it's Alexa or Google Assistant or ChatGPT. Prompt engineering as an interaction paradigm is helpful because it makes this responsibility explicit and teaches users techniques for interacting more effectively.
If language interfaces themselves can't be usable by the masses and without manuals, that's a limitation of the current technology, not an inevitability.
But day-to-day language—the language we use to talk to other people, to negotiate, to plan things together, to chitchat, to get things done, the type of language that's accessible to everyone—doesn't work this way.
How People Actually Talk
The conduit metaphor and prompt engineering as a paradigm are based on two fundamental assumptions: that people have a specific meaning in mind and that it's one person's responsibility to put that meaning into words to impart to the other. Neither of these aligns with the primary way in which people engage in language interactions. Instead, people use language to shape meaning and messages with one another. Let's take a look.
Myth 1: People have a specific or fully formed meaning in mind. When we sit down to craft a presentation or write a paper, we spend time and effort thinking about exactly what we want to convey and how. But that's very different from how we approach interactive dialogue (spoken or written). At a mechanical level, people start interacting while they're still thinking, developing the language of the message in increments, before it is fully formed. People interact even when they're still uncertain about what they intend [4].
We see this very directly in how people engage with technology as well. We recently conducted a study where we looked at people's touchpoints with technology as they planned a trip, made a large purchase, or learned more about a hobby. These are all information- and inspiration-seeking journeys that people often do over weeks or months. We found that in the many phases of a planning and research journey, the actual "execution" phase (i.e., the point at which a user knows exactly what they want and are ready to act on it) is at the tail end of a much longer iterative process. People shape and develop their questions and understanding of the domain and even of their needs and wants along the way. They often don't have a fully formed and specific need they can articulate at the start. For instance, a person might do many searches, over many weeks, using the vague word heels until they learn enough to know that what they are actually looking for is black suede 2.5-inch pumps. The person doesn't have the domain knowledge or the vocabulary at the beginning to articulate an exact need [5].
So maybe when you're asking DALL-E for a picture, you know exactly what you want and just need to find the right words to get the right output (as in the prompt engineering example in Figure 2). But most often, people will begin engaging with all kinds of technology, including GenAI, before they know exactly what they want and need—even before having a specific meaning in mind.
Myth 2: It's one person's responsibility to convey meaning. The power of language is that it enables people to coordinate, shape, and refine meaning together. That's how people most often use language, and it's what enables interactions to be spontaneous, incremental, and relatively effortless. We rely on one another to shape both the content and the form of the interaction. We provide and seek feedback, refer to and extend shared context, and make incremental contributions to clarify or accept, and those same processes affect the success of language-based human-computer interactions (see [6] for an overview). People instinctively tailor their contributions to their current context and partner, adjusting their words, syntax, and style to accommodate the shared common ground and sociocultural knowledge between them [7]. The consequence is that effort is distributed between people ("shared effort") through social coordination, rather than one person assuming the entire responsibility for the success or failure of an interaction.
In our research, we also see this instinct and need in how people engage with technology. When people engage with LLMs, they ask for suggestions, refer to shared history and context, and build on previous responses. Their top expressed need is for systems to have a back-and-forth with them, to help them learn, to help them narrow things down, and to let them know what the system needs to provide better responses. Currently, they feel they do all the work of finding tailored information. But their request isn't that AI take over; rather, they want to do this refining and thinking together. We hear from people that this type of interaction increases the likelihood that the content will be relevant and useful, exposes them to new information, and makes the interaction feel more personal [5].
So while the old language-as-conduit metaphor has been useful for unlocking language patterns, it's not enough to get us all the way to understanding. It's always been limited in its ability to explain how people actually use language to arrive at shared meaning and get things done.
Maybe, for the next frontier of AI interactions, we need a new paradigm.
A New Paradigm for Language Interfaces: Work with Me
In the 1970s and 1980s, a new understanding of language interactions emerged from complementary fields of study, including ethnographic conversation analysis, computer science, psycholinguistics, and cognitive science. Inspired and informed by how people interact with one another, they arrived at a new paradigm; following Herbert H. Clark [8], we'll call it language as action. This approach holds that language is a joint action between two or more people who are coordinating their actions and understanding with one another. So when we speak or write, we are not simply encoding our thoughts and ideas into symbols; we are also trying to get others to do something, or to understand our perspective, which can only be successful with the others' active participation and context. We're not "passing" meaning back and forth like a package—we are cocreating it, jointly coming to a shared understanding and definition of the situation and constraints.
What are the implications for today's technologies? The incredible leap forward in language interface capabilities means that people can focus on what they need as opposed to how to get there. Our colleagues at the Nielsen Norman Group (NNG) recently referred to this new AI paradigm as intent-based outcome specification [1]—the user tells the computer the desired result, but does not specify how this outcome should be accomplished. Compared with traditional command-based interaction, NNG argues, the new paradigm shifts the locus of control entirely from the user to the machine.
We propose that future HCI will be grounded in an interactive and iterative approach to mutual human-AI understanding.
While we agree the new user interface paradigm affords a move from "command-based" to "intent-based" interactions, we suggest that the future is much more about shared control (i.e., collaboration), where both human and machine work to understand and refine intents. Specifically, we propose that future HCI will be grounded in an interactive and iterative approach to mutual human-AI understanding (i.e., to the problem of "specification alignment" in AI models [9]). This future of shared control is one where the AI provides contextual, grounded dialogue contributions that help the user evolve and revise their intent, and the outcome. In fact, NNG alludes to this: "[R]ounds of gradual refinement are a form of interaction that is currently poorly supported, providing rich opportunities for usability improvements for those AI vendors who bother doing user research to discover better ways for average humans to control their systems."
What we've learned about how people talk hasn't yet been fully leveraged in our speech technologies—we're still in the paradigm of (en) coding queries. But we can explore new paradigms that take these truths into account: People don't always have the right words. They don't always know what they need or what the system knows (or needs to know). Planning and research take a long time and help build domain and requirement knowledge; execution is just the tail end. And finally, people want systems to share effort with them to help them evolve their intents and refine their meaning. That's how they use language with one another, and it's their default expectation for using language with an AI.
New explorations in LLM modeling are already demonstrating the benefits—both technical and user facing—of training models to behave more like this; for one example, see a paper by Belinda Li et al. [10], who trained a model to elicit more information about a user's task through free-form interactive dialogue. Another example is recent work on social reasoning in LLMs, a critical step toward achieving a model of what a particular user might know (and eventually how best to engage with them) [11].
The language-as-action paradigm provides a well-motivated, well-researched psycholinguistic foundation for a collaborative approach to language interactions in which the system's goal is to progress mutual understanding through shared effort, a goal that will sometimes be achieved in a single query-response turn, and often will not. This approach inspires us to open our technologies to accommodate both highly specific queries as well as ones that are more vague, exploratory, and uncertain. We can do this by building our systems with the ability to behave more collaboratively: to ask relevant questions, to offer multiple potential paths to help the user evolve their knowledge and intent, and to provide evidence of progress toward shared understanding. It has implications as well for the longevity of collaborative systems, maintaining and resurfacing shared knowledge over time, and for foundationally integrating the social and contextual dynamics of interactions.
Conclusion
The leap forward in GenAI and LLMs bring with it an incredible opportunity to define a new HCI paradigm that moves us away from being an "expert tool" and into a more accessible, natural interface for all. Much of our design and development approach to language technologies is rooted in the idea that language is a product of an individual's thought, a means to transmit information from one person to another. Thus, we have prompt engineering to teach us how to package up our thoughts in very specific language so that AI can decode or "understand" it, affording users fine-grained control over the output. But this isn't how most language interaction works, nor does it capture the power of language to facilitate interactions (and action). There's a well-motivated, well-researched psycholinguistic foundation for a more collaborative approach to language interactions, where humans and computers share effort to collectively shape the intent and direction of the output, refining and elevating the final result. This approach represents exciting possibilities for how we interact with and leverage AI in the future: language interfaces that don't require teaching people how to talk to computers, but rather scaffold on fundamental human interaction behaviors.
References
1. Nielsen, J. AI: First new UI paradigm in 60 years. NN/g. Jun. 18, 2023; https://www.nngroup.com/articles/ai-paradigm/
2. Schaffer, S. and Reithinger, N. Conversation is multimodal: Thus conversational user interfaces should be as well. Proc. of the 1st International Conference on Conversational User Interfaces. ACM, New York, 2019, Article 12, 1–3; https://doi.org/10.1145/3342775.3342801
3. Reddy, M. The Conduit metaphor: A case of frame conflict in our language about language. In Metaphor and Thought. A. Ortony, ed. Cambridge Univ. Press; 1993 (orig. 1979), 164–201; http://www.biolinguagem.com/ling_cog_cult/reddy_1979_conduit_metaphor.pdf
4. Gussow, A.E. Language production under message uncertainty: When, how, and why we speak before we think. In Psychology of Learning and Motivation: Speaking, Writing, and Communicating (Vol. 78). K.D. Federmeier and J.L. Montag, eds. Academic Press, 2023; https://doi.org/10.1016/bs.plm.2023.02.005
5. Kraljic, T. and Lahav, M. Helping users refine their intents: A collaborative opportunity for genAI. Submitted, 2024.
6. Brennan, S.E. The grounding problem in conversations with and through computers. In Social and Cognitive Psychological Approaches to Interpersonal Communication. S.R. Fussell and R.J. Kreuz, eds. Lawrence Erlbaum, Hillsdale, NJ, 1998, 201–225.
7. Raczaszek-Leonardi, J., Debska, A., and Sochanowicz, A. Pooling the ground: Understanding and coordination in collective sense making. Frontiers in Psychology 5 (2014); https://doi.org/10.3389/fpsyg.2014.01233
8. Clark, H.H. Using Language. Cambridge Univ. Press, Cambridge, U.K., 1996.
9. Terry, M., Kulkarni, C., Wattenberg M., Dixon L., and Ringel Morris, M. AI alignment in the design of interactive AI: Specification alignment, process alignment, and evaluation support. arXiv:2311.00710, 2023; https://doi.org/10.48550/arXiv.2311.00710
10. Li, B.Z., Tamkin, A., Goodman, N., and Andreas, J. Eliciting human preferences with language models. arXiv:2310.11589v1, 2023; https://doi.org/10.48550/arXiv.2310.11589
11. Gandhi, K., Fränken, J.P., Gerstenberg, T., and Goodman, N.D. Understanding social reasoning in language models with language models. arXiv preprint arXiv:2306.15448, 2023; https://arxiv.org/abs/2306.15448
Authors
Tanya Kraljic is a staff user experience researcher at Google Research. Her work advocates for human-centered solutions to emerging technologies, from language technologies to climate-mapping tools. She holds a Ph.D. in cognitive psychology and has led research programs in industry and academia, most recently focusing on generative AI systems, multimodal HCI, and AI memory. [email protected]
Michal Lahav is a staff user experience researcher at Google Research. Her research areas include human-centered approaches to generative AI, memory, machine translation, and assistive speech technologies. Her research supports incorporating global perspectives, community-based research practices, and helping AI be more equitable for underrepresented communities. [email protected]
 This work is licensed under a Creative Commons Attribution International 4.0 license.
This work is licensed under a Creative Commons Attribution International 4.0 license.
The Digital Library is published by the Association for Computing Machinery. Copyright © 2024 ACM, Inc.




Post Comment
No Comments Found